9. Februar 2023
LIVIA-AI − Künstliche Intelligenz für Kunstsammlungen
Gemeinsam mit dem Belvedere und dem Wien Museum nimmt das MAK am KI-Projekt LIVIA-AI (Linking Viennese Art through AI) der Universität Wien, der Donauuniversität Krems und des Austrian Institute of Technology teil. Im Fokus dieser Kooperation steht, wie Künstliche Intelligenz helfen kann, Kunstsammlungen miteinander zu vernetzen, museale Sammlungen besser zu verstehen und der Öffentlichkeit leichter zugänglich zu machen. Christian Michlits und Julia Santa-Reuckl, die Projektverantwortlichen des MAK, stellen für den MAK Blog das Projekt LIVIA-AI näher vor.
Als der Jubiläumsfonds der Stadt Wien 2021 Förderprojekte zum Thema Digital Humanities: Neue Potenziale durch Artificial Intelligence in den Geistes-, Sozial- und Kulturwissenschaften suchte, taten sich Nicole High-Steskal (Donau Universität Krems), Rebecca Kahn (Universität Wien) und Rainer Simon (AIT Austrian Institute of Technology) zusammen und reichten mit Erfolg ihr Projekt Linking Viennese Art through AI – LiviaAI ein. Mit einer Fördersumme von über 80.000 Euro und einer Laufzeit von einem Jahr (März 2022 bis März 2023) untersucht LIVIA-AI das Potenzial von künstlicher Intelligenz (KI), um Muster, Verbindungen und Assoziationen zwischen digitalisierten Objekten in drei Wiener Sammlungen zu identifizieren. Hier kommt das MAK mit seiner umfangreichen, transparenten und vielfältigen Sammlung ins Spiel. Neben dem Belvedere und dem Wien Museum beteiligte sich das MAK mit dem Löwenanteil von rund 200.000 Datensätzen an dieser vielversprechenden Kooperation.
Projektziele
Sammlungen verstehen:
Wie kann KI genutzt werden, um museale Sammlungen besser zu verstehen? Als Werkzeug für Wissenschaftler*innen und Kuratoren*innen soll KI dazu dienen, Sammlungsdaten im großen Maßstab zu untersuchen, insbesondere um zu veranschaulichen, wie verschiedene Museen im Laufe der Zeit unterschiedliche Sammlungspraktiken und Klassifikationsschemata angewandt haben.
Sammlungen vernetzen:
Kann KI helfen, Verbindungen zwischen Sammlungen und einzelnen Objekten sichtbar zu machen? Mit dem Ziel der Herstellung von Verbindungen zwischen Online-Sammlungen können Assoziationen respektive Ähnlichkeiten zwischen den Sammlungen und ihren einzelnen Objekten besser sichtbar gemacht werden. Auf diese Weise werden institutionelle Grenzen überwunden.
Sammlungen erkunden:
Wie können die Ergebnisse zur spielerischen Erkundung von Sammlungen eingesetzt werden? Im Rahmen des Projekts soll ein interaktiver Webauftritt entwickelt werden, der es der Öffentlichkeit ermöglicht, durch die von der KI aufgedeckten Verbindungen zu navigieren.
Projektverlauf
Metadata-Clustering:
Zunächst mussten die von den beteiligten Sammlungen bereitgestellten Daten verarbeitet werden. Mit Hilfe der Machine Learning-Verfahren Sentence Embedding und Graph Embedding wurde ausgehend von den Eigenschaften eines Objektdatensatzes, unter Berücksichtigung von Daten wie Objekttitel, Objektbeschreibung oder thematischer Beschlagwortung, jedem Objekt ein Punkt beziehungsweise Vektor in einem Raum zugeordnet. Je ähnlicher die Metadaten zu einer Abbildung beschaffen waren, desto näher lagen die Punkte/Vektoren aneinander. Dieser Vorgang wird als Metadata-Clustering bezeichnet. Nahe beieinanderliegende Objektpunkte werden dabei als „good neighbours“ bezeichnet.
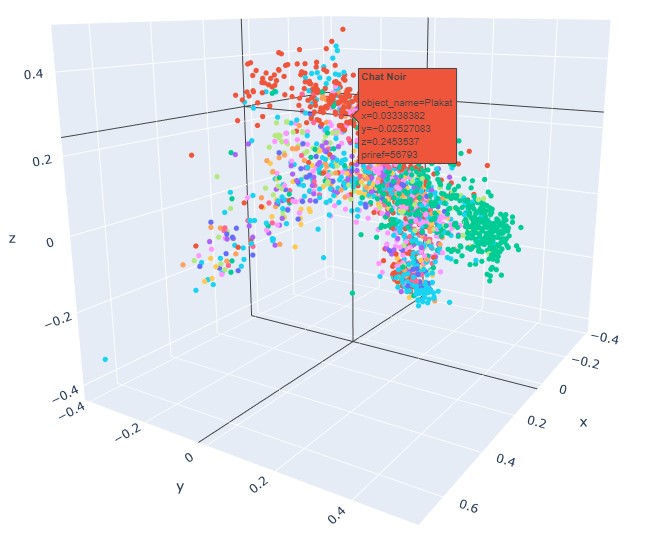
Punktwolke der MAK-Daten
© Rainer Simon, AIT
Relativ rasch wurde offensichtlich, dass Ähnlichkeiten in Bezug auf das verwendete Vokabular nur innerhalb der einzelnen Sammlungen nachvollziehbar sind, aber nur bedingt sammlungsübergreifend. Zu unterschiedlich ist trotz aller Vokabulare und Normdaten die Beschlagwortung beziehungsweise zu unterschiedlich sind die Sammlungen zusammengesetzt. Die fehlende Ähnlichkeit in den Metadaten zwischen den einzelnen Sammlungen wurde schon vor Projektbeginn nicht nur vermutet, sondern war sogar die eigentliche Motivation für die Entwicklung der KI. Letztlich sollte ohnehin ein Programm entwickelt werden, das Ähnlichkeiten primär aufgrund von Abbildungen erkennt, nicht anhand der bereits vorhandenen Metadaten.
Triplets:
Zum Erlernen von Ähnlichkeiten wurde mit Dreiergruppen von Bildern, so genannten Triplets, gearbeitet. Zwei der Bilder sollten einander ähneln, das dritte weiter abweichen. Aus den im Rahmen der Embedding-Verfahren errechneten Punktwolken wurden jeweils zwei nebeneinanderliegende Punkte (good neighbours) und ein entfernter Punkt zu einem Triplet zusammengestellt. Das Erlernen von Ähnlichkeit basierte also auf Ähnlichkeiten der Beschlagwortung. Die Annahme im Projekt war aber, dass die KI durch die Beispielbilder letztendlich auch sinnvolle visuelle Ähnlichkeitsmerkmale erlernen kann.
Gut konzipierte Triplets ermöglichten es also der KI, Ähnlichkeiten zu „erkennen“. Das Ergebnis wird auch als Image Embedding bezeichnet, weil hier – anders als bei Sentence oder Graph Embeddings – ein Vektor direkt aus der Bildinformation errechnet wird. Was genau die KI als ähnlich identifiziert, lässt sich nicht ausschließlich objektiv beschreiben. Zunächst geschieht das durch die mitgelieferten semantischen Daten. Hier kann trocken berechnet werden, wie viele Übereinstimmungen – beziehungsweise wie viele Abweichungen – sich in den Objektdaten finden lassen. Dabei lauert allerdings die Gefahr, durch die Auswahl der verwendeten Daten die KI zu stark zu beeinflussen. Die KI sollte also doch vorwiegend anhand von Bilderkennung Ähnlichkeiten identifizieren. Dabei blieb es für die KI offen, ob sie die Verbindungen anhand von Formen, Farben oder anderen Aspekten herstellte.
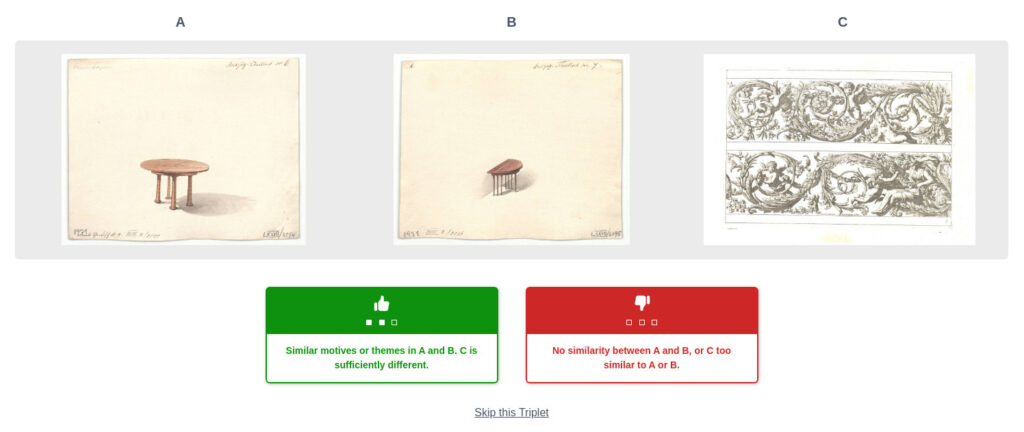
Rate-this-triplet: Beispiel MAK
Screenshot: © Rainer Simon, AIT; für die einzelnen Abbildungen im Bild © MAK
Im Rahmen des Projekts gab es auch die Möglichkeit für Interessierte, Triplets nach ihrer Ähnlichkeit zu bewerten. Naturgemäß spielte bei der Bewertung und Beurteilung von Triplets die menschliche Subjektivität eine große Rolle. Auf diese Weise konnte dem Lernprozess der KI aber auch ein nicht-maschineller Aspekt mitgegeben werden.
Ergebnisse
Das Endergebnis all dieser Lernvorgänge ist eine schlichte Anwendung, die ähnliche Abbildungen von Objekten anzeigt. Der Einstieg erfolgt über einen Suchbegriff. Als Suchergebnis werden maximal 25 Treffer angezeigt, die als Raster von fünf mal fünf quadratischen Abbildungen angeordnet sind. Diese erste Suche basiert noch ausschließlich auf den Metadaten. Bei der Auswahl einer der angezeigten Abbildungen kommt schließlich die KI zum Einsatz und gruppiert um das selektierte Auswahlbild, das nun in die Mitte des Rasters rückt, 24 als ähnlich erkannte Abbildungen.
Demovideo
 © Rainer Simon, AIT
© Rainer Simon, AIT
Über ein oben rechts platziertes Steuerelement kann der Radius der Ähnlichkeit erweitert werden: Je weiter der Kreis nach rechts geschoben wird, desto großzügiger ist der Bereich, aus dem die KI „ähnliche“ Bilder durch Zufallsprinzip auswählt.
Das Reload-Icon in der linken oberen Ecke lädt eine neue zufällige Bilderauswahl, daneben kann mit einem neuen Suchbegriff eine weitere Suche gestartet werden. Über die Lupe in der rechten unteren Ecke der Bilder kann eine Detailansicht des Werks mit Titel und Link zum Objekt in der Sammlung Online des entsprechenden Museums aufgerufen werden. Links unten in der Detailansicht gibt es die Möglichkeit, ein Bild in den Warenkorb zu legen. Die im Warenkorb gesammelten Werke sind dann über das entsprechende Icon rechts oben auf der Seite abrufbar. Die Anwendung ist noch bis Ende Februar 2023 online abrufbar: Willkommen bei LIVIA-AI!
Zukünftige Anwendungsmöglichkeiten der KI
Die im Rahmen des Projekts entstandene Anwendung könnte in Online-Sammlungen eingebunden werden, um Nutzer*innen einen zusätzlichen Aspekt der Erkundung anzubieten. Die Ermittlung von Suchergebnissen kann durch das „Wissen“ der KI entsprechend erweitert werden. Davon können sowohl externe Anwender*innen mit ganz unterschiedlichem Background als auch „Museumsinsider*innen“ wie Marketingverantwortliche oder Kurator*innen profitieren. Nachdem wir die KI beim Anlernen tatkräftig unterstützt haben, sind wir sind bereits sehr gespannt, was wir in Zukunft unsererseits von ihr lernen dürfen.
Wie weitreichend die Fähigkeiten künstlicher Intelligenz bereits sind, wird uns derzeit durch die anhaltende Berichterstattung zum prominenten Chatbot ChatGPT vor Augen geführt. Das Potenzial der Auskünfte ist so groß, dass der Bot eigens darauf programmiert wurde, spezielle Themen auszusparen und gewisse Fragen unbeantwortet zu lassen. Um den aktuellen Stand zu demonstrieren und eine KI-Geschmacksprobe abzugeben, wollten wir ursprünglich Chatbot ChatGPT bitten, den letzten Absatz für diesen Blog-Beitrag zu schreiben. Warum ChatGPT der Bitte derzeit nicht nachkommen kann, erklärt er selbst – im Stile Shakespeares:

ChatGPT erklärt sich à la Shakespeare
Screenshot ChatGPT, Stand: 16. Jänner 2023
Ein Beitrag von Christian Michlits, Leitung Digitales MAK und Julia Santa-Reuckl, Digitales MAK




